

文|三易生活
如今,人工智能毫無疑問已經是科技行業最為熱門的賽道之一,甚至幾乎所有叫得上名號的科技企業都卷入了這場競賽。而在AI大模型的相關市場競爭中,除了底層的算法、架構外,“語料”則是一個被反復提及的關鍵要素。但圍繞“語料”這一AI大模型的生產資料,在過去一年間,整合行業也上演了一系列光怪陸離的故事。
那么訓練AI大模型的語料從何而來呢?自然是從書籍、報刊、雜志、視頻、音頻、代碼等,一系列凝聚了人類智慧的產物中來,但是由于AI不是人類,他們認識世界的方式與人類不同,所以蘊含在這些作品中的信息還需要經過一道處理工序,才能轉化為可以被AI大模型利用的語料,而這就是所謂的“數據標注”了。
比如OpenAI旗下的ChatGPT,就是靠著2美元時薪的海外外包數據清洗人員,完成了史無前例的1750億參數量、45TB的訓練數據。
如果把人工智能比作一棟大樓,那么標注的數據就是一塊塊的磚,如果將人工智能比作一碗飯,那么標注的數據自然也就是大米了。從某種意義上來說,現階段的人工智能在實質上其實就是字面上的意義,也就是50%的人工+50%的智能。如果沒有人工數據標注的存在,那么當下的AI大模型競爭恐怕是要直接“熄火”。
有鑒于此,谷歌方面近期表示要讓人工智能更智能一些。

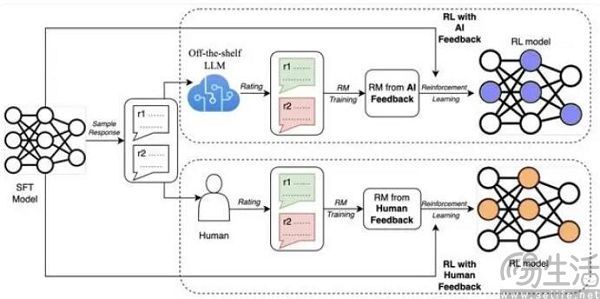
日前,Google Research的最新研究提出了AI反饋強化學習(RLAIF),用來代替基于人類反饋的強化學習(RLHF)。事實上,RLHF正是ChatGPT等同類產品表現出比Siri等上一代人工智能產品更聰明,表達更接近人類的關鍵驅動因素之一,它可以借助人類反饋信號來直接優化語言模型,數據標注人員則通過給大模型產出的結果打分,由他們來負責判斷大模型生成的文本是否優質(迎合人類偏好)。
根據谷歌方面的研究結果顯示,RLAIF可以在不依賴人類標注員的情況下,產生與RLHF相當的改進效果。具體來說,當被要求直接比較RLAIF與RLHF的結果時,人類對兩者的偏好大致相同,同時RLAIF和RLHF都優于傳統的監督微調(SFT)基線策略。這也就意味著谷歌的研究證明了用AI訓練AI大模型并非空話,也代表著如今的人工智能行業很有可能會迎來一次大規模的洗牌。
眾所周知,語料是AI大模型的基礎,而AI大模型之所以比以往的同類產品表現得更“聰明”,單純就是因為語料的規模更大。例如GPT-3就擁有的1750億的參數量、45TB的訓練數據,GPT-4的參數規模則達到了驚人的1.8萬億。但要將基礎數據轉化為AI可識別的語料,無疑是個巨大的工程。
數據標注就是把各種圖片、文本、視頻等數據集打上標簽,成為計算機可以理解識別的技術。這一工作在2007年之前是由程序員來負責完成,但畢竟有限的程序員群體與AI對于語料的無止境需求極其不匹配,所以這也導致了AI在本世紀第二個十年以前一直都曲高和寡。直到2007年,計算機科學家李飛飛通過亞馬遜眾包平臺雇傭了167個國家共計5萬人,來給10億張圖片篩選、排序、打標簽,最終構建了ImageNet數據集。
自此之后,大量科技企業發現數據標注并不需要程序員來參與,只要是受過一定教育的普通人即可完成,這也成為了為什么AI在近十年來突飛猛進的原因之一。其實數據標注從某種意義上來說,就與流水線上工人干的活沒什么區別,而對著電腦屏幕根據給定的規則來給數據打上各式各樣的標注這一工作,完全可以稱得上是“賽博搬磚”。
相關廠商顯然不會將自己寶貴的人力資源浪費在這樣機械化的工作上,所以數據標注目前基本就是一個以外包為主導的行業,并且通過BPO的形式將數據標注工作交付給外包公司,確實也在一定程度上為AI廠商節約了成本,但從客觀上來說,數據標注本身還是很費錢的。雖然0.25元/條是過去兩年數據標注行業的均價,但別看單價沒多少,可數以億計的規模就直接讓數據集的總價變得可觀了起來。

看到這里,有的朋友可能會有這樣的疑問,如果谷歌提出的RLAIF真的可行,數據標注人員是不是要失業了?畢竟數據標注人員一天能完成800到1000條的數據標注就已經是優秀水平了,但比起不眠不休、不會疲勞的AI,血肉構成的人類還是沒得比。更有效率、更穩定的情況下,一旦再證明了RLAIF的效果不輸RLHF,人類進行數據標注顯然將會不再有經濟性。
如果單純從商業層面出發,RLAIF肯定要比RLHF更好,但問題是AI廠商作為人類社會的一份子,同樣也具有社會性,并且AI廠商打造的大模型不僅要有性能,更重要的是還要合規。如今ChatGPT、New Bing在性能上比它們剛亮相時有所衰退的原因,已經不僅僅來自用戶的體感,更得到了研究人員的證實。
其實這一現象并非是因為OpenAI、微軟的技術退步了,反而是兩者技術迭代的結果,因為他們必須要在AI倫理問題上合規。由此也衍生出了一個控制AI的概念“AI對齊”,即要求AI系統的目標要與人類的價值觀與利益對齊,不會產生意外的有害后果,比如說暴力、歧視等。例如現在向文心一言提出幫你想一個罵人的話,文心一言就只會直接回答,“作為一個人工智能語言模型,我不會提供或使用任何形式的臟話或粗俗語言。”
但問題也就來了,網絡上大家互相攻擊的言論可謂是數不勝數,文心一言怎么可能會做不到罵人呢?但它確實可以很“正能量”,這其實就是“AI對齊”在發揮作用。可強行讓AI遵守人類的價值觀本身就是反直覺的,在微軟研究院發布的一篇論文中就已經證實,對AI大模型所進行的任何AI對齊行為,都會損失大模型的準確性和性能。

所以現在的情況,就是谷歌提出的RLAIF本質上是剝離了AI大模型訓練中的人類參與,但這與“AI對齊”的思路是相悖的。雖然在谷歌的相關論文中,RLAIF與人類判斷呈現出高度相似,但目前在圍繞AI的爭議如此巨大的情況下,真的有企業敢于去用RLAIF來代替RLHF嗎?