

文|三易生活
此前在5月15日舉行的I/O開發者大會上,谷歌CEO納德拉向外界正式介紹了AI搜索功能AI Overviews(AI概覽)。在谷歌Gemini大模型de 驅動下,AI Overviews能夠在谷歌搜索的頁面頂部總結提煉用戶查詢內容的概要。在許多業內人士看來,AI Overviews無疑是谷歌搜索引擎上線25年以來最大的一次革新,以至于谷歌方面敢于宣稱該功能將重新定義搜索體驗。
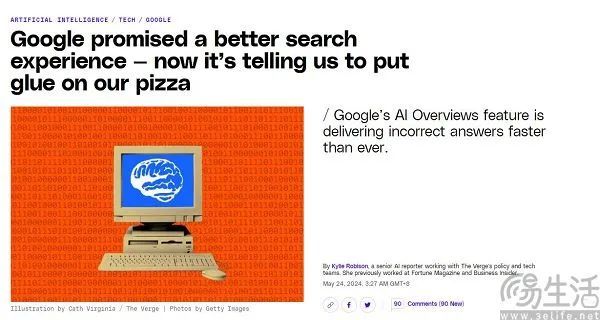
但遺憾的是,搶先體驗了AI Overviews的美國用戶對于“重新定義搜索體驗”持不同意見。例如The Verge的記者Kylie Robison就在文章中諷刺了AI Overviews的翻車。她在文中舉了一個例子,就是當用戶查詢如何將芝士和披薩餅胚粘在一起的時候,AI Overviews的回答是,“加點膠水”。盡管膠水確實可以解決粘連問題,但這極有可能是Gemini出現了“幻覺”(Hallucination)所導致的結果。
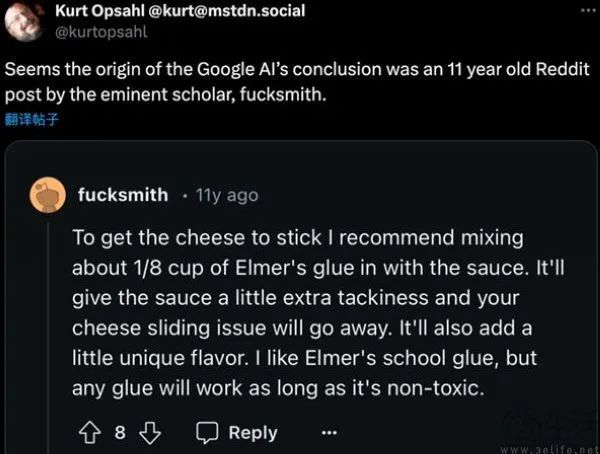
AI大模型會出現“幻覺”,這如今幾乎是人盡皆知的事情,谷歌公司發言人Meghann Farnsworth似乎也是按照Gemini因“幻覺”翻車來解釋的。他表示,“這些錯誤來自通常非常罕見的查詢,不能代表大多數人的體驗”。但神通廣大的網友很快給出了AI Overviews會回答“在披薩上涂膠水”的理由,因為這個回答實際上來源于一個名為“fucksmith”的Reddit用戶在11年前發的帖子。
AI Overviews會采納Reddit用戶的帖子來作為回答并不奇怪,因為谷歌與Reddit在AI搜索上是有合作的。
AI Overviews的前身是Search Generative Experience(SGE),它是谷歌推出的一種實驗性版本的搜索引擎。在美國谷歌選擇了Reddit作為合作伙伴,為用戶提供更精準、及時的搜索解答。其實使用Reddit的數據并不奇怪,可問題是谷歌為什么會采信這種明顯出現常識錯誤的數據。

所以最有可能的解釋,是谷歌在數據清洗上出現了紕漏,以至于讓“有毒”的數據進入了Gemini的數據集。如果事實果真如此,那么在某種意義上就證明了谷歌為了在AI賽道追趕OpenAI,已經急功近利到走火入魔的地步。因為在此之前,谷歌在大模型的數據清洗上已經翻車過一次。
去年年末、也就是Gemini上線不久后,就有國內網友發現用中文向Gemini Pro提問時,Gemini Pro會直接表示自己是百度的文心一言。緊接著在更多的網友提問下,Gemini Pro一會認為自己是小愛同學,一會又承認自己是悟道大模型開發團隊北京智源做的。
對此,當時業內人士的主流觀點,是谷歌在訓練數據上大概率使用了百度文心一言的輸出結果,以此來蒸餾自家的Gemini Pro。要知道,OpenAI已經證實了大模型的“幻覺”問題和數據質量息息相關,數據投毒攻擊(Data Poisoning Attack)也已經是一個AI領域不可回避的問題。
根據研究人員在HITCon安全會議上的演講顯示,只需要“污染”不到0.7%數據就可以完全繞過防御,進而全面降低大模型輸出內容的準確率。用謊言去驗證謊言得到的一定是謊言,如果數據集中的參數本身就有問題,那么得到的回答自然就會是錯漏百出。因此數據清洗一直以來都是AI廠商最為重要的工作之一,幾乎所有的大模型都會加入數個糾錯和屏蔽措施,避免數據庫遭受有毒信息的污染。
更為關鍵的是,谷歌可是做搜索引擎起家的,而搜索引擎的核心技術就包括了數據清洗,將爬蟲抓取的數據中存在的缺失值、異常值(離群點)、重復值去除,就都是數據清洗的一部分。結果他們在AI業務上卻接二連三地因為數據清洗問題翻車,這顯然不是個正常的現象。
反常背后必然有原因,在許多海外網友看來,谷歌從AI賽道領跑者的位置滑落,進而不得不追趕OpenAI的現實,可能導致了他們變得如此急躁。
過去一年間,AI初創企業Perplexity就被視為是谷歌的挑戰者,而這家公司被投資者看中的原因也很簡單,因為它做的是AI搜索。并且就在此次I/O開發者大會舉行前,OpenAI也被曝出將要做AI搜索來挑戰谷歌,因此AI Overviews更像是谷歌對于Perplexity和OpenAI的回擊。或者說在此次I/O開發者大會上,谷歌無論如何都得展現出自己對AI搜索的態度,即便沒有AI Overviews、也得有AI abstract。
只不過急功近利必然是有代價的,用戶使用搜索引擎是希望尋求答案,可AI Overviews給出的答案卻是偏頗的,這無疑就是在動搖大眾對于谷歌搜索的信任。作為這家公司最為核心的產品,谷歌搜索應該是穩健的,但現在谷歌卻把一個實驗性質的功能直接推向數以十億計的用戶,這不是急功近利又是什么?