
文|飛說智行
智能駕駛行業的發展有多卷?
要回答這個問題很簡單,看看車企、自動駕駛公司和智駕方案供應商們追逐的技術焦點變換得有多快就行了。
去年下半年開始,蔚來、小鵬、理想和比亞迪等車企們向智能駕駛領域快速地奔跑起來,紛紛提出了自身“輕地圖、重感知”的城市NOA落地時間表,甚至華為和小鵬等企業還更進一步,想要做到真正無圖的城市NOA。
一時間,BEV+Transformer和OCC占用網絡等一系列的技術名詞,就成為了整個智能駕駛行業的熱詞,推進落地開城和直播智駕過程也成為了眾多車企展現自身技術優勢的最直接方式。
殊不知,這樣卷了半年時間,從今年初開始,由于受到了特斯拉的啟發,整個智能駕駛行業的風向快速轉變——齊刷刷盯向了端到端技術(End-to-End)。
最近,理想汽車舉辦了智能駕駛夏季發布會,首次公開展示了其端到端自動駕駛技術架構,該架構主要由端到端模型、VLM視覺語言模型、世界模型三部分共同構成,也就是其CEO李想此前提到的“系統1”和“系統2”,他們也宣布這套系統是部署到車端的智駕方案。
蔚來和小鵬,自然也沒有慢下腳步。前者近期在內部單獨設立了一個大模型部門,專門負責端到端系統的研發工作,蔚來方面也對飛說智行表示,下半年在智駕方面他們會有很多動作。
小鵬汽車在今年5月也發布了量產上車的端到端大模型——由神經網絡XNet+規控大模型XPlanner+大語言模型XBrain構成,其掌門人何小鵬也宣布小鵬汽車到2025年將在國內實現L4級別智駕體驗。
除了“蔚小理”之外,長城汽車、比亞迪和廣汽等國內自主車企,商湯絕影、華為、騰訊、百度Apollo和元戎啟行等科技企業,也在今年紛紛公布了各自在端到端領域的計劃和落地進展,端到端技術由此就成為了整個行業競逐的關鍵技術標的。
從追求BEV+Transformer,到競逐端到端技術方案,這屬于企業戰略層面的變化。但與此同時,由于上一代方案還未很好落地、下一代方案就來了的現實,如何快速變換研發策略,也考驗著每一家企業的智駕研發團隊們。
以上這些企業之所以會紛紛競逐端到端技術,也是因為這一技術被行業大多數人視為是突破目前智駕領域天花板的有效方法,誰能搶到這一技術的高地,誰就能取得較大的行業優勢。
只不過,也有人認為端到端技術并不是智駕行業未來的唯一路徑,那么端到端是智能駕駛行業的終局嗎?智能駕駛行業競逐的終點到底在哪里?在目前還未看清前路的行業背景下,這些問題值得討論。
01 摸到“天花板”后,行業奔向端到端
技術的變革,往往是由問題推動的。
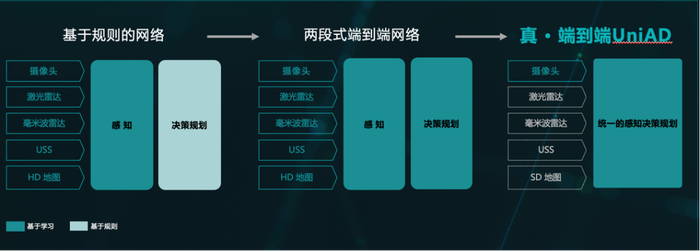
一般而言,實現高階智駕,要基于智駕算法為基礎。前些年,行業普遍采用的是傳統自動駕駛算法方案,即感知-決策-規劃-控制的多模塊算法,這套算法雖然在面對簡單駕駛場景上表現較好,但在處理復雜的高階智駕場景時,就會出現較多的瓶頸。
首先是在開城速度和體驗上,由于多模塊智駕算法架構是基于人類編寫的代碼和規則驅動的,在遇到不熟悉的Corner cases時會出現明顯的頓挫感,同時在泛化性方面也有明顯不足,導致拓展新城市時效率不足。
另外,雖然很多車企喊出了輕圖或者無圖的口號,但在智駕系統運行時依舊會或多或少利用到高精地圖資源;還有在算法訓練方面,模塊間都需要人工規控和訓練的干預,這些都增加了車企的成本壓力。
這樣的技術問題,一時間成為了整個智駕行業共同面對的困境。但與此同時,一篇論文的出現,為整個行業帶來了啟示。
去年6月,一篇名為《Planning-oriented Autonomous Driving》(以路徑規劃為導向的自動駕駛)的論文出現在行業面前,該論文因為提出了感知決策一體化的端到端自動駕駛通用大模型UniAD,獲得了2023全球計算機視覺盛會CVPR最佳論文獎。
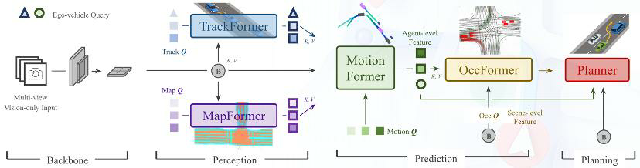
這一端到端算法模型,首次將檢測、跟蹤、建圖、軌跡預測,占據柵格預測以及規劃整合到一個基于Transformer的端到端網絡框架下,把全棧的自動駕駛任務整合到一個網絡中,簡言之,就可以讓算法實現從感知輸入直接輸出路徑決策的過程。
使用端到端技術來構建智能駕駛算法的直接好處,可以減少傳統模塊化算法信息傳遞時的噪音和減損,來提升整體算法運行的效率。此外,由于端到端算法無需人工編寫冗余的規則和代碼,大大降低了人工成本的同時,神經網絡算法還具備較強的泛化能力,可以提升智駕系統落地和開城的效率。
學術研究帶來啟示后,產業落地快速跟進。
特斯拉成為率先吃端到端這只“螃蟹”的車企之一。去年8月,特斯拉FSD V12 版本問世,按照當時其官方的介紹,這一版本可以實現“一端輸入攝像頭等傳感器獲得的數據,另一端直接輸出車該怎么開。”由此這一版本也被國內一些媒體同行宣傳為“端到端技術正式上車”。
這之后,一邊是埃隆·馬斯克通過社交媒體表示“FSD V12通過神經網絡,人工編程的 C++控制代碼由30萬行縮減到了3000行”來體現端到端技術的優勢;另一邊,隨著今年2月FSD V12在美國開啟推送后,其絲滑且流暢的路測視頻也讓整個智駕行業為之震動。
特斯拉領頭后,“蔚小理”等眾多車企們迅速開始追趕。
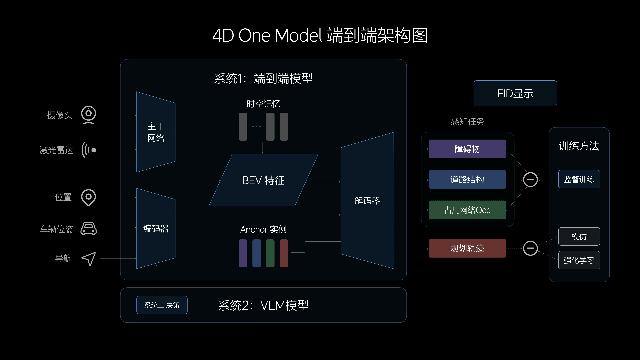
去年12月,理想汽車宣布完成了OTA5.0更新,按照其官方介紹,基于端到端架構,實現了對BEV大模型、MPC模型預測控制以及時空聯合規劃等能力的整合,同時他們還使用了OCC占用網絡和神經先驗網絡NPN作為架構補充。
再到上周,理想系統化地展示了他們在端到端自動駕駛算法架構,并且提出了端到端“4D One Model”架構,輸入傳感器信息,輸出行駛軌跡。但需要注意的是,這一架構思路類似于上文提到的端到端自動駕駛通用大模型UniAD架構。
以智能化為標簽的小鵬汽車,在今年1月全國智駕啟動發布會也宣布端到端大模型會在未來全面上車。四個月后,他們就發布了量產上車的端到端大模型——神經網絡XNet+規控大模型XPlanner+大語言模型XBrain。
在小鵬汽車智能駕駛技術負責人李力耘看來,“XBrain、XNet、XPlanner,既有聯系又有分工,能夠非常好地提升AI智駕能力上限。”

對于蔚來來說,在端到端大模型方面采用的是漸進式的路線。在他們看來做端到端大模型的前提是要讓智駕各功能模塊都已形成模型化,具備足夠的性能和工程效率。
簡單說就像是先有每塊功能化的拼圖,然后組裝為整張端到端的完整拼圖,不然就像蔚來智能駕駛研發副總裁任少卿認為的那樣“否則端到端就是個毒藥。”
這兩天,蔚來推送了Banyan 2.6.5版本,其中包括端到端的AEB功能,可以讓AEB避險能力顯著增強。隨著今年6月蔚來內部智駕團隊架構完成調整后,蔚來也成為了率先量產端到端智駕功能的車企。
除了特斯拉,“蔚小理”之外,其他車企也加到這場端到端大模型的競逐賽中。
比如長城汽車就推出了名為“SEE”的端到端智駕大模型,從前段時間的重慶全場景NOA路測效果來看,實現復雜路段絲滑且流暢通行的同時,還能兼具安全和效率。
同為自主車企的比亞迪,也在最近宣布已完成端到端無圖方案的開發,目標要做到智駕第一梯隊;長安汽車,也提出了將BAV感知和LLM(大語言模型)端到端融合的構想。
車企之外,諸多自動駕駛企業和科技大廠也在紛紛擁抱端到端技術。商湯絕影就在今年的北京車展上,展示了UniAD架構的實車上路成果,僅靠7顆攝像頭組成的視覺感知,讓車輛實現在城區乃至鄉村道路環境中無圖高階智駕的能力。
作為國內自動駕駛第一梯隊企業的小馬智行,在去年8月就把感知、預測、規控三大傳統模塊打通,統一成端到端自動駕駛模型,目前已同步搭載到L4級自動駕駛出租車和L2級輔助駕駛乘用車。
騰訊、百度和華為、也沒有慢下來。騰訊在今年4月發布了行業首個汽車行業大模型,并設立了“專云專用”的智能汽車云雙專區,為自動駕駛開發創造了一個端到端、全程合規的數據閉環服務。
同在4月,百度Apollo發布了支持L4級自動駕駛的端到端大模型ApolloADFM,以聯合訓練的方式實現端到端無人駕駛。按照最新的消息,蘿卜快跑第六代無人車已經全面應用了ApolloADFM大模型+硬件產品+安全架構的方案。
華為同期也發布了基于端到端大模型的ASD3.0智駕系統。感知部分采用GOD(General Object Detection,通用障礙物識別)的大感知網絡,決策規劃部分采用PDP(Prediction-DecisionPlanning, 預測決策規控)網絡實現預決策和規劃一張網。
就在整個智能駕駛行業快速奔向端到端技術的同時,對于端到端技術的能力和邊界的思考也在進行著。
02 端到端技術的“冰山問題”
冰山,往往很多人只看到了20%的水面以上部分,而水面之下80%的部分卻很容易被忽略。對于端到端技術來說,同樣存在這樣的“冰山問題”。
就像上文提到的可以降低傳統智駕算法的模塊間信息損減、提升信息的傳輸效率,以及降低算法訓練成本和提升泛化效果等等,都屬于端到端技術對于智能駕駛算法構建的優勢,也就是大多數人看到的那20%部分。
但這些端到端的好處,無法做到瑜能掩瑕,畢竟端到端技術的不足和缺陷,也就是藏在“水面”以下的80%,是真實存在的。
眾所周知,要訓練端到端智能駕駛,算力、算法和數據三大要素缺一不可。其中,獲取數據對于擁有大規模量產車型的車企和擁有自動駕駛車隊的自動駕駛企業來說,看似并不是什么難事。
而實際情況是,要訓練端到端算法,需要海量且質量較高的數據才行。按照馬斯克在去年透露的信息,他們在訓練FSD時一般會用到上千萬個視頻素材,假使每個視頻以30秒來計算,訓練端到端模型的數據起碼需要幾萬小時的視頻素材。
全球最大的自動駕駛公開數據集Nuplan此前發布的數據,他們的數據規模達到了1200小時,這些數據還不是為端到端自動駕駛所準備的。
按照小馬智行CEO樓天城的話來說:“要訓練一個高性能的端到端模型,對數據的要求可能是幾個量級的提升,這是自動駕駛行業都會面臨的挑戰。”
由于端到端自動駕駛模型很少用人工進行規控,從而就讓用于訓練的數據變成了“指導”端到端算法學習的“老師”,對于數據質量的要求自然會大幅提升。
數據不僅要有場景的全流程演繹,同時還需要是具備人類老司機級別的駕駛行為和多元的案例集合,從而讓每個素材都有屬于各自的know-how。為此,需要在海量的數據中挖掘真正有用的素材。
就比如前文提到的特斯拉幾萬小時的視頻素材,就是他們從超過20億英里的FSD里程數據中挖掘出來的。而此前特斯拉FSD V12.4.2版本被推遲推送,其原因也是因為給算法“投喂”太多不合適的素材,以至于需要重新調整權重后重新訓練。
數據之外,隨著端到端模型的走紅,也對算力的需求越來越高。
按照公開數據顯示,截至去年8月,特斯拉已經能提供10000 PFLOPS規模的算力。此外特斯拉還在建設Giga Texas數據中心,到今年10月預計其算力可提升至100000 PFLOPS。
國內智駕行業也早早打響了算力的“軍備競賽”。比如在2022年,小鵬汽車就聯合阿里云智能計算平臺建設了“扶搖”自動駕駛智算中心,算力可達600 PFLOOS;基于他們在年度算力訓練費用方面超7億元的投入,這一算力目前應該也有明顯增長。
再到去年,理想汽車也基于火山引擎建立了自己的智算中心,算力至少能達到750 PFLOPS。
與理想和小鵬相似的是,蔚來找來了騰訊做“外援”,合作建立智算中心,雖然截至目前并未公布算力的情況,但就公開的數據顯示,蔚來智能駕駛端云算力本月新增20.56 EOPS,目前總算力已達287.1 EOPS。
車企卷起來的同時,華為、商湯絕影和毫末智行等智駕供應商們也不甘示弱。
以華為的云智算中心為例,根據公開數據其算力已經達到了3500 PFLOPS,訓練數據量為日行3000萬公里;商湯大裝置布局的全國一體化智算網絡,總算力規模可達到12000 PFLOPS,而到了今年底算力預計可提升至18000 PFLOPS。
毫末智行,也在2023年1月與火山引擎合作建設了名為“雪湖·綠洲”的智算中心,其算力可達到670 PFLOPS。而在這之前的2022年,毫末就開始對端到端模型進行研發和探索,基于雪湖·綠洲,毫末也在加快端到端的研發進度。

只不過,相比于特斯拉的算力規模,“蔚小理”、以及華為、毫末等國內企業的算力還是有較大的差距。
不能否認,算力與數據的制約,也在很大程度上影響算法的迭代,再加上被視為“引路人”的特斯拉,或許意識到了被競爭對手“逐幀研究”智駕算法后,叫停了AI Day的舉辦,從而讓它身后的一眾企業沒了“摸石頭過河”的機會。
以至于,縱觀目前的智能駕駛行業,在端到端研發方面,雖然呈現出百花齊放的熱鬧景象,但行業面對的共同問題,也無法在短期內找到解法,就比如說行業內老生常談的可解釋性問題。
由于端到端模型沒有模塊間可表達的中間結果,以至于人類算法工程師無法確認各個模塊的確定性和安全性,從而增加了整體算法發生錯誤的風險和參與調試的難度,這也是行業內常說的“黑箱”問題。
看到這一問題后,行業中有些企業也試圖解決。就比如英國自動駕駛企業Wayve.AI,就嘗試把VLAM(視覺語言動作模型)引入多模態大模型中,讓車輛LINGO系列模型與車內乘客文字對話,以便提升整體算法的可解釋性。
毫末智行,在面對這一問題時,與Wayve有著相似的思路。他們引入LLM(大語言模型),并與其交互和提建議等措施,來提升算法對世界的理解和可解釋性。但毫末智行CEO顧維灝也認為,LLM存在較為嚴重的幻覺,來指導自動駕駛算法有較大的風險。
除了可解釋性問題,測試方法不成熟、車載芯片算力不足和企業組織投入分配等方面,也是構建端到端智駕模型過程中不可忽略的諸多問題。
基于以上這些潛在水面以下的問題,也讓目前火熱的端到端技術走向了矛盾的處境中,智能駕駛行業對其的認識也有了不同的分歧和思考。
03 智能駕駛行業的終局在哪里?
對于端到端的認知,智駕行業并不像看上去的那樣“團結”。
按照辰韜資本發布的《端到端自動駕駛行業研究報告》顯示,在他們對智駕行業進行一系列調研后發現,行業對于端到端大模型的態度存在不同的陣營。
比如在對智駕行業技術終局的預判方面,有46%的比例認為是端到端是智駕行業技術的終局方案;還有50%的比例則認為端到端只是未來眾多方案中的其中之一,以及4%比例的受訪者認為端到端僅是過渡方案。
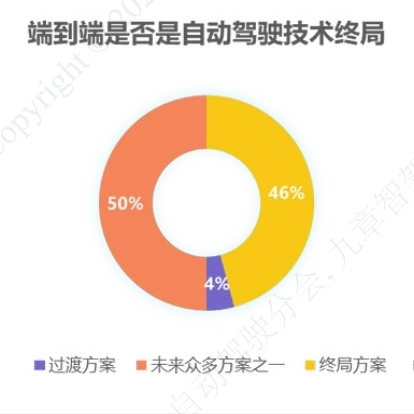
這一數據的分布,也印證了上文的分析,由于端到端技術的正式發展才剛剛起步,還有諸多的問題缺乏討論和解決落地,以至于對于智駕行業技術終局的發展方向難以達成共識也在情理之中。
那么,對于智能駕駛行業來說,技術的終局到底在哪里?
對于智能駕駛行業的發展過程,在地平線創始人兼CEO余凱看來主要有三大時代——可用(1.0時代)、好用(2.0時代)和愛用(3.0時代)。會有這三個時代,也是因為智能駕駛功能的核心還是需要回歸到消費者的本質,換句話說智能駕駛最終是消費者在使用的。
在飛說智行看來,目前智能駕駛行業已成功邁過可用的1.0時代,正無限接近好用的2.0時代,距離愛用的3.0時代還有較大的距離。
按照蓋世汽車研究院統計的數據顯示,2024年初國內L2及以上等級智駕系統的滲透率為42.4%,但根據高工智能研究院的數據顯示,目前高階智駕的滲透率還不到10%,這也意味著消費者對于高階智駕的接受程度還不足。
飛說智行此前向一些智能汽車車主詢問“會經常開啟使用車上的智能駕駛功能嗎?”得到的答復大多數是不經常使用,即便很多主流車型已經具備城市NOA,也有很多車主表示只會在高速和高架上使用,到了城區后還是會自己開,主要原因還是不好用。
“相比于高速和高架,城區道路不確定性的情況會更多,如果開啟城市NOA后,不僅要時刻緊盯車輛前方的路況,做好隨時接管的準備;同時還得無時無刻去判斷車輛算法是否對路況做出正確的判斷和處理,真不如自己開的輕松。”智能汽車車主汪涵這樣對飛說智行表示。
在城區里開啟智能駕駛功能,開100公里、300公里、500公里接管一次,消費者的體驗完全不一樣。正因這樣,目前各家車企和自動駕駛企業對于算法的打磨和迭代,都是為了能邁過好用這一門檻。
而對于愛用的標準,在余凱看來需要系統提供擬人化的駕駛體驗,不僅保證行駛的物理安全,還要給駕駛員提供心理的安全感。要做到這一目標,還有較大的距離。
除了消費者這端之外,人工智能和大模型本身的涌現能力,也會成為決定智能駕駛終局走向的重要因素。
2022年,在一篇名為《Emergent Abilities of Large Language Models》的論文中,研究人員們把LLM在一段時間內能力的突然躍升現象稱之為“Emergent”(涌現)。
這一術語很快被廣泛用于人工智能和大模型經過訓練后,出現的出乎意料的新行為和功能,且這些行為可能與初始訓練目標無關。從最早的AlphaGo、到之后的ChatGPT和GPT-4,再到如今的Sora,都被行業視為人工智能涌現能力的體現。
“有理由相信,隨著人工智能和大模型技術在之后被更多應用到智能駕駛算法的構建中,這樣的涌現現象也會繼續出現,帶領智能駕駛和自動駕駛技術實現進化和迭代。”國內頭部智能駕駛企業研發負責人孫濤這樣對飛說智行表示。
基于以上這些分析,在飛說智行看來,并不完美的端到端技術屬于現階段智能駕駛行業的最優解,但隨著眾多車企、自動駕駛企業以及上下游產業鏈對于技術的探索,未來或許還會誕生更加全面且完善的算法和技術,由此加速整個行業終局的到來。
雖然智能駕駛行業技術終局的到來還很遙遠,就像日出前漫長的黑夜一樣,但對于該行業的從業者們來說,也許并不為此擔憂或者恐懼,因為他們相信這一天總會到來。
正像劉慈欣在《三體—黑暗森林》結尾寫的那樣:“太陽總會升起來的”。
(應受訪者要求,文中汪涵和孫濤為化名)