
文|新眸企服組 桑明強
要說最近企服圈什么最被關注,SaaS和數據中臺想必是大多數人心里的答案。
前者商業模式已經被證明,Salesforce就是最好的例子,后者從剛出現時的火熱,到被質疑跌落谷底只用了短短3、4年時間。這讓很多人好奇,為什么在“數據價值已經被證明”和“企業數字化轉型也成了多數CEO共識”的當下,大家對于數據中臺的看法還會呈現兩極分化,看好的人堅定認為數據中臺是企業數字化轉型的“解藥”,看衰的人規勸同行不要上中臺,它是雞肋,是“毒藥”。
歸根結底,是因為業界對一個關鍵問題的看法還沒有達成一致,即數據中臺究竟是不是支撐企業數字化轉型的最合理的數據基礎架構?翻譯一下就是,數據中臺能不能滿足企業數字化轉型的最大公約數,或者說媒體老師們口中的最優解。
數據中臺是一個“新物種”,但它的新僅僅停留在國內廠商的造詞能力上,它誕生于國內,不懂技術的人容易被“中臺”二字帶偏,誤以為它是一副萬能藥,在硅谷,其實也有一些知名獨角獸公司有著和數據中臺架構相類似的數據基礎架構,但他們習慣把它叫作數據平臺,而不是數據中臺。
這里我們需要明確的是,所謂的“數據中臺”,它只是一種叫法,就像“人工智能”一樣,具體定義和內容往往需要根據要實現的目標和要解決的問題來確定。以Twitter為例,公司從2011年的300人,發展到2014年的4000人,大數據平臺從80臺服務器的單純Hadoop集群,擴展到8000臺服務器的核心數據處理平臺,打從在很小規模時,Twitter就是一家數據驅動型的公司,而它管理的底層支撐,是一個全局共享的大數據平臺。
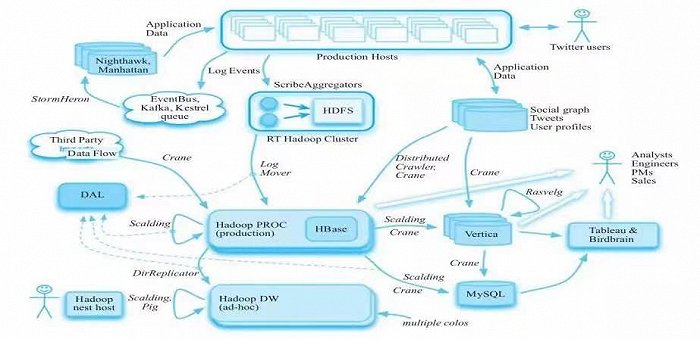
圖:Twitter大數據平臺架構(來源:《云原生數據中臺:架構、方法論與實踐》)
這種平臺型架構的好處是,Twitter在業務和組織快速擴張時,能做到統一數據規范、消除數據和應用孤島。回到國內,多數企業在搭建數字化信息系統時,也就是在頂層設計的初期,并沒有做到面向未來,所以一旦組織擴張速度過快,數據層面的浪費和組織層面的冗余也就隨之而來,在這種情況下,企業往往盲目寄托于上數據中臺,把包袱丟給數據智能服務提供商,但卻忽略了自身的癥結關鍵所在,所以難免越做越錯。
一般來說,數據智能有3個發展階段:大數據平臺建設階段、數據管理及應用階段和數據能力中臺化階段。就目前來看,大部分企業的數據平臺建設已經進行到一、二階段,但要順利過渡到第三階段,就繞不開一個關鍵方法論的幫助——DataOps(數據運維),值得一提的是,它是很多硅谷公司在解決第三階段問題時普遍采用的方法論。
DataOps由DevOps概念衍生而來,是基于元數據開發和部署數據分析應用的一種靈活敏捷的方法。“它讓數據開發過程變得敏捷可控,這是眼下很多公司最頭疼的事。對于大多數企業來說,數據在調整過程中容易缺少版本管理、缺少持續集成,甚至沒有測試環節,整個過程都要靠人去做這件事情,他們就像是數據管道工,更別談最終形成你想要的AI模型。”滴普科技FastData產品管理部總經理曾這樣談到,無獨有偶,《數字化轉型架構:方法論和云原生》一書中也明確提及,云原生應用平臺的發展將經歷DevOps—DataOps—AIOps的演進路徑。為此,這篇文章我們將主要探討:
1、為什么有的數據中臺不能成功?
2、突然崛起的DataOps究竟是什么?
3、追求DataOps,為什么要回歸第一性原理?
01、為什么有的數據中臺不能成功?
數據中臺成熟后,會不會變成類似數據倉庫和數據湖一樣的數據基礎架構,可能是大多數人最為關心的問題,但這對于數據中臺的發展來說,其實是一件好事,原因在于它把問題收窄了,回歸到數據中臺的產品本質上,也就是基本面問題。
和以往技術中間件不同的是,雖然數據中臺也承接底層數據和上層業務的中間層,但它的價值更多地體現在與企業業務結合的能力矩陣維度,而不是簡單地做一些數據標準化和報表工具。所以這里就涉及到能用和好用的問題,同時也是當下的主流問題:做一個能用的數據中臺不難,但要做到好用甚至說持續好用,非常難。
在滴普科技看來,“這和國內企業數字化的進程有關,很多企業本身就有自己的一些信息系統,大多數在數字化升級時,都是基于現有基礎改造,而不是從0到1摸底建設,這對于數據智能服務商挑戰極高。”背后的原因很簡單,一般來說,傳統信息系統往往建立在多個數據倉庫之上,而數據中臺會使用數據湖來存儲,但根本問題是,分割的數據層無法對核心業務流程進行全局還原和支持,也無法實現數據驅動的全局決策和產品研發。
前文提到的Twitter就是最好的例子,在2011年以前,Twitter開發和發布產品的流程非常冗長,產品經理需要到各個部門調研可以使用的數據,并協調數據的生產化問題。在數據平臺推行后,Twitter整個產品的開發和迭代流程從以月計改為以周計,活躍用戶數也從2011年不到1億,增長到2014年接近3億。在當時Twitter大數據項目負責人看來,“這是架構上的勝利。”
同理到現在的環境也是一樣,隨著自助服務分析和機器學習的迅速發展,公司里的管道數量也隨著數據分析師、數據科學家、數據工程師以及數據使用者業務部門增多而增多,問題的關鍵是,幾乎每一個都需要專門的數據集和數據訪問權限才能產生內容,而協調這些工具、技術和人員是一項巨大且耗費精力的工作,特別是在規模龐大的開發團隊里,這也解釋了為什么DataOps會發展起來。
溯源企業數據平臺項目的失敗案例,你會發現它們往往都有一些共性,比如初期啟動難,得不到業務支持、很難把數據源規模化,缺少對復雜源數據系統的管理手段、數據平臺項目跟不上企業創新要求以及開發和運營成本極高,無法正向反哺業務。
以往的經驗告訴我們,很多時候,一個高速發展的業務往往是因為早期架構設計的問題,變得難以迭代。所以從這個角度看,并不是數據平臺的理念過時了,而是數據中臺的架構過時了。因為除了確定對于業務的價值外,建設數據平臺的根本性問題是技術架構的選擇和設計,但這相當于給一架高速行駛的列車更換引擎,難度系數很高。
02、突然崛起的DataOps究竟是什么?
前文我們提到,DataOps是硅谷公司在解決第三階段問題時普遍采用的方法論,同時也是數據中臺建設必須參考的一個方法論,這在一定程度上證明了DataOps的可行性。眾所周知,數據智能要解決的三大問題是數據處理、模型搭建及交付,想要實現智能工程化或者大規模可持續的數據智能交付,現在業內公認的模式運維解法是ModelOps,開發運維解法是DevOps,至于數據運維,就是DataOps。
在2018年Gartner發布的《數據管理技術成熟度曲線》報告中,DataOps概念被首次提出。
維基百科對DataOps的定義是一種面向流程的自動化方法,由分析和數據團隊使用,旨在提高數據分析的質量并縮短數據分析的周期,簡而言之,就是提供一整套工具和方法論,讓數據應用的開發和管理更加高效。但Gartner也指出,DataOps雖然可以降低數據分析的門檻,但并不會讓數據分析變成一項簡單的工作,與DevOps的落地一樣,實施成功的數據項目也需要做大量的工作,比如深入了解數據和業務的關系、樹立良好的數據使用規范等。
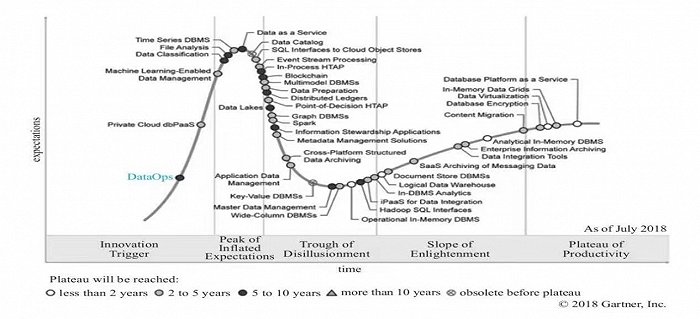
圖:Gartner對DataOps的定位(來源:Gartner官方)
就像前文我們所提到的,DataOps的誕生并不是偶然,IBM商業價值研究院曾有過一份研究:數據科學家往往需要花費大量時間準備、驗證和清理數據源,然后才能使用這些數據源訓練數據模型,因此他們只能用少得可憐的一點點時間,去設計用于將數據轉化為價值的AI模型。據估計,AI部署過程中有80%的工作都用于準備數據。
如果從第一性原理出發,你會發現DataOps與數據中臺需要解決的問題其實是相類似的,它們都希望能更快、更好地實現數據價值,實現數字化運營,但兩者側重點卻有所不同。
前者強調的是數據應用的開發和運維效率提升,類似于DevOps解放了開發人員的生產力,后者強調的是數據統一管理和避免重復造輪子,是對數據能力的抽象、共享以及復用。
上升到產品原教旨主義層面,如果說數據中臺強調的是戰略層次的布局,即必須有一個中臺來承擔所有數據能力的管理和使用,那么,DataOps強調的就是戰術維度的優化,即如何讓各個開發和使用實際數據應用的人員更加高效,換句話說,數據中臺只是粗線條地描述了最終目標,而DataOps提供了一條更加精細化的最佳路徑。
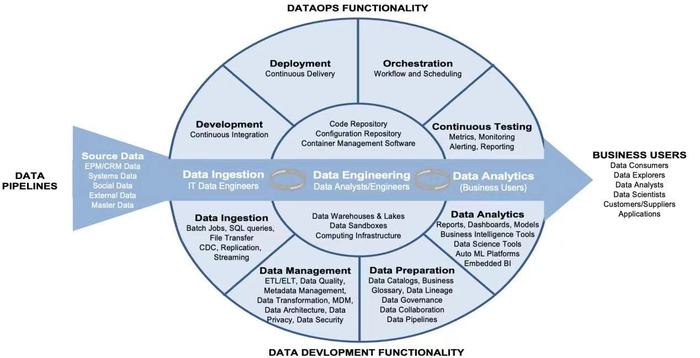
圖:DataOps架構(來源:Diving into DataOps: The Underbelly of Modern Data Pipelines韋恩·埃克森)
當然,這和DataOps的架構有關。按照技術層面的解釋,DataOps重點放在了數據中心,為用戶提供了一系列數據工具,并通過人員協作與流程管控的模式,實現持續的數據科學模型部署,這可以通俗理解成“編排”,同時也是DataOps核心靈魂所在,因為一個好的編排工具意味著它能協調數據開發項目的4個組成部分,包括代碼,數據,技術和基礎架構。
因此,在云智能時代,DataOps是面向5G多云復雜部署數據處理的有效手段,也極有可能成為數據中臺的發展拐點。
03、追求DataOps,需要回歸第一性原理
DataOps的優勢顯而易見,比如它能改善數據管理者和數據消費者角色之間的溝通,讓雙方處于同一頁面上;整合整個企業的數據流,并通過數據管道自動化降低運營成本;通過良好的監控,保證可靠性和可觀察性。
滴普科技方面認為,“擁有更強大的數據管理能力,是面向未來的架構關鍵特征。以當下主流的分析型數據庫湖倉一體為例,想要完成湖倉一體的最終建設,則必然要經歷以下三個階段:數據入湖——數據治理和質量——DataOps。”
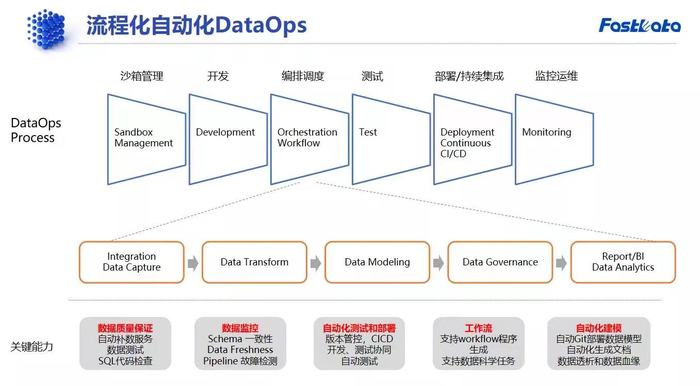
圖:DataOps開發流程(來源:滴普科技官方)
但這并不意味著它是一副萬能藥。
就像前文所述,雖然DataOps可以降低數據分析的門檻,但不會讓數據分析變成一項簡單的工作。與DevOps相類似,DataOps的使用與發展,也是一個需要有正確工具和正確思維加持的持續過程,它的目標是用正確的方式實現數據智能項目落地,解放數據的功能屬性,形成生產力。
在數字化浪潮里,企業數據平臺要想成功落地,是雙向選擇和奔赴的過程,就像種一棵樹,你不能頭天種下了,第二天就希望它能變成木材,而是觀察它的底部究竟在不在生長。
在2018年IBM和Forrester Consulting聯合發布的報告《數字化轉型的深層實質》中,數字化轉型的任務由3個主要系統承擔:SoE(System of Engagement,行動系統)、SoI(System of Insight,洞察系統)以及SoR(System of Record,記錄系統)。SoR主要把系統需要的數據記錄下來,SoI負責從數據中發現洞見,而SoE負責根據洞見來引導行動,雖然數字化轉型的模型可能有多種表現方式,但你會發現,它的主要功能和建設內容還是繞不開這三個方面。
延續到客戶視角來看,他們往往希望廠商能提供完整數據平臺的搭建以及端到端的技術能力,并提供相關行業的知識和洞察,但這通常會牽涉很多賽道,從數據存儲、數據處理、數據整合、到數據治理、人工智能、機器學習,再到最終的BI,而這些賽道的技術差異是很大的,所以對于數據智能服務玩家來說,需要用第一性原理思考問題:有所為,有所不為。