
文|真探Alphaseeker 吳鴻鍵
“最近大模型的涌現,比大模型能力的「涌現」都要快。”
「涌現」是一個專業概念,放在大模型的語境里,指的是模型在突破某個規模時,出現了意想不到的能力。這話雖然是調侃,但也高度概括了行業現狀。
ChatGPT在全球掀起熱潮以來,國內已有多家公司發布或將發布自己的大模型,這些公司中既有阿里巴巴、百度、京東、華為等互聯網或科技大廠,也有以商湯為代表的AI公司,以及備受矚目的初創企業(例如王慧文的光年之外,王小川的百川智能)。
如果再把科研院所算上,據民生證券的統計,國內目前已有超30個大模型亮相。行業儼然有大模型“軍備競賽”的意思。
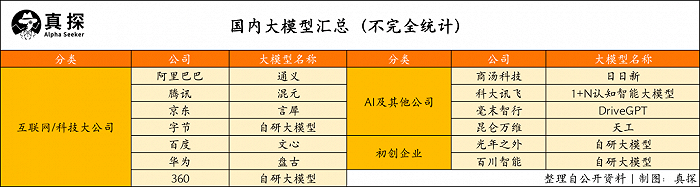
“混戰”本身說明了不少事情,比如各家都已認識到大模型的價值,試圖通過大模型升級已有業務和打開新增長空間。即使人們普遍認為大模型門檻高,但“百花齊放”也折射出業界認為大模型的發展尚處早期,且并不是只有極少數大玩家才能參與的游戲。
機會看上去很多,但撥開冗雜的信息,我們需要判斷,大模型的“涌現”是不是曇花一現?以下四點值得關注。
產業融合成共識
相比ChatGPT在用戶端的熱潮,國內廠商更愿意談大模型和產業的結合。“客戶”是高頻詞,“接入我們的大模型”是共同目標。
以阿里巴巴的通義大模型為例,近期,阿里云官宣自研大模型“通義千問”并面向企業開始邀請測試,在阿里云峰會上,包括張勇在內的阿里云高管頻頻強調大模型能為各行業企業帶來的價值。據阿里云智能CTO周靖人介紹,未來企業在阿里云上既可以調用通義千問的全部能力,也可以結合企業自己的行業知識和應用場景,訓練自己的企業大模型。
早些時候發布“文心一言”的百度,也是將B端“生態圈”作為宣傳和業務重點。華為云盤古大模型提出了“AI for Industries”理念。推出大模型“日日新”體系的商湯,更是只面向政企客戶開放API。
大環境對于生成式人工智能服務相對謹慎的態度、企業各自的資源和能力稟賦、以及在C端體驗上和ChatGPT的差距,都可能是造成差異的原因。上述案例的共性是,大模型對于各家企業并非一個“另起爐灶”式的新業務,而是對已有業務方向的延伸和突破,對大模型的理解依然要放在公司已有的業務發展框架里來看。
依然以阿里云為例,云計算公司容易陷入“低毛利集成商”困境,難以在標準化和定制化之間找到平衡。預訓練大模型帶來了新的可能——在阿里云方面的設想中,企業只需將數據放在專屬數據空間,用于大模型自動學習,然后就能生成企業專屬的大模型。相比原本“什么都要從頭做”的業務模式,大模型提供了效率更高的選擇。
揚長避短,各秀肌肉
目前,國內的大模型廠商并不諱言和OpenAI、ChatGPT的差距,只是各家對于“差距有多大”有一些不同的判斷。
相比OpenAI,國內互聯網大廠有成熟的業務矩陣,多元的能力架構,以及在多年實戰中鍛煉出來的差異化能力,因此大公司們愿意強調的能力和方向也有所不同。
例如張勇在云峰會上表示,阿里巴巴所有產品未來都將接入“通義千問”大模型。此舉意在利用大模型升級甚至改造現有業務體系,阿里云方面將這種融合視為未來發展的關鍵,稱“阿里巴巴和所有企業都在同一起跑線上”。
除了拿自家業務當試煉場,阿里云還在峰會上提及其他優勢,比如指出大模型的研發不是簡單的“堆疊算力”問題,強調阿里云在低碳低能耗方面的能力積累。這也是阿里云提出為企業打造專屬大模型的重要原因。
百度的優勢來自其在中文搜索引擎的領導地位,因此公司在發布文心一言時,著重強調了其“更懂中文”的特性。商湯則更多強調其在參數和算力上的優勢。“日日新”體系包含自然語言處理模型“商量”(SenseChat)、文生圖模型“秒畫”和數字人視頻生成平臺“如影”(SenseAvatar),其中“商量”參數約1800億。商湯方面還強調,SenseCore大裝置已完成2.7萬塊GPU的部署,并實現了5.0 exaFLOPS的算力輸出能力,最高可支持萬億參數超大模型的訓練。
除了應用,在和大模型相關的芯片和框架方面,國內大公司也有現成的積累。百度有昆侖芯、深度學習框架飛槳,華為有昇騰310和910芯片,ModelArts平臺。這些同樣是大廠在發展大模型時著重利用的對象。
大模型不稀缺,高質量數據才稀缺
大模型“混戰”還反映了一個信息:至少從表面上看,大模型不再稀缺。
民生證券在研報中指出,因為有開源基礎以及大公司自本身的算力儲備和資金實力,“單純發布一個大模型的門檻沒有市場想象中的那么高”。
“有大模型”不難,難的是“有一個能持續迭代,性能不斷提升的優質大模型”。一些觀點也提到,決定大模型發展的關鍵要素是高質量數據,尤其是在大模型“百花齊放”的背景下,數據是“勝負手”。
數據、算法、算力是AI能力三要素。
高質量的數據是助力AI訓練與調優的關鍵,在和數據相關的流程中,數據采集、數據標注和數據質檢又是較為重要的三個環節。但相比大模型的熱鬧,目前國內的數據相關產業鏈還有不小的提升空間。
據“自象限”的觀察,目前數據質量在國內尚未受到足夠重視,缺乏專門做數據質量的企業,這類企業更多是以大公司附庸品的形態出現。
而在海外,數據質量形成了垂直賽道,其中的公司會幫助AI企業最大限度地減少劣質數據帶來的影響,這類公司產品通常包括數據可觀察性平臺、數據整理和偏見檢測工具,以及數據標簽錯誤的識別工具等等。
到底需不需要這么多大模型?
最后是一個靈魂之問:行業需不需要這么多大模型?或者說,在大廠相繼發布大模型的背景下,新玩家還有沒有加入混戰的必要?
大佬們對此有不同的看法。早些時候李彥宏在接受采訪時表示,現在國內大廠都看好AI大模型,創業公司重新做沒有多大意義。相較而言,“基于大語言模型開發應用機會很大,沒有必要再重新發明一遍輪子”。
并不是所有人都認同這一觀點。根據“品玩”的采訪,王小川認為“大模型就是需要時間長一點,認真一點,而錢也不是唯一重要的”,“有些公司雖然有大模型這個底子,但沒碰好就練歪了,上戰場更難受。”
由于大模型的門檻和不確定性,留給中小廠商以及創業公司的難題還有很多——規模跟不上大公司的節奏,中模型或小模型難以找到競爭點,也難以獲得“涌現”機會。如果選擇垂直場景切入,又有可能遭遇來自通用大模型的“碾壓”,一如ChatGPT對Jasper.AI的沖擊。
大部分關于這類問題的討論,比如要不要做大模型,要做什么樣的大模型,要選擇什么樣的場景來落地等等,目前都還處于“混沌”狀態。不少人在表達觀點時還會特意強調“就目前的情況看”,并表示自己未來可能會在觀點上有搖擺。但行業普遍認為,大模型代表著大機會,最后只有少數玩家能留下。