

中國人民大學科學研究處、中國人民大學信息資源管理學院:錢明輝、楊建梁
當人工智能走出實驗室、邁向產業化的深水區,數據已不僅是模型訓練的原材料,更是支撐智能系統不斷演進的核心資源。隨著大模型、多模態、具身智能等新范式持續推進,傳統由單一機構提供數據的方式已難以滿足對數據規模、數據質量、更新頻率和語義深度的多重需求。在這一背景下,以開放數據集為基礎、以多元主體協同機制為支撐的“開放數據集生態”逐漸成型。這一生態不僅推動了人工智能技術的規模化應用,也正在重塑數據治理模式與社會協同機制。
相關閱讀:

知識蒸餾與數據萃取:開發人工智能訓練所需的“動態食譜”與“黃金食材”
一、開放數據集生態構建:來源結構與實踐探索
開放數據集是指在符合安全、隱私和倫理規范的前提下,向社會公眾開放訪問、使用、標注和再開發的數據資源集合,涵蓋文本、圖像、音頻、視頻等多種模態。根據來源與用途可大致分為四類:一是政府開放數據,包括地理信息、公共服務、政務文件、統計年鑒等,強調公共可治理性;二是科學研究數據,涵蓋高能物理、基因組學、天文觀測等領域,注重可驗證性與共享精神;三是行業運行數據,如制造流程、金融交易、物流配送等,體現行業知識密度與流程特性;四是社會眾包數據,如用戶上傳圖片、開放問答、平臺交互日志等,富含社群認知特征與場景多樣性。
在全球范圍內,開放數據生態建設已積累了較為豐富的經驗。美國通過Data.gov平臺集中發布環境、交通、教育等政務數據集,NASA、USGS等機構則向科研人員開放遙感、氣象、地質等高價值科學數據集。歐盟以《開放數據指令》為政策抓手,構建了跨國數據共享機制,推動成員國間數據互通。Kaggle、UCI等學術平臺則廣泛提供機器學習、計算機視覺、自然語言處理等標準數據集,支撐機器學習和算法驗證。
中國的開放數據體系起步較晚但發展迅速。國家統計局、自然資源部、生態環境部等政府部門已上線多個數據平臺,涵蓋統計、地圖、水文、氣象等領域;在科研領域,“國家科技資源共享服務平臺”“科創中國”等項目整合了高校和研究機構的數據資源;產業方面,百度、阿里、華為等頭部企業陸續開放語音識別、圖像識別、自然語言處理等任務數據集,推動AI基礎模型訓練。然而,國內數據平臺在標準規范、接口透明度、更新頻率等方面仍有改進空間,高價值行業數據(如醫療、金融)受限于隱私與安全監管,仍未實現有效開放。

這一生態系統的形成,是技術變革、資源配置與治理需求共同推動的結果。從技術角度看,大模型需要從泛化智能走向行業智能,必須依賴真實、豐富的場景數據;從資源角度看,數據分散存儲在政府、企業和個人中,單一機構難以獨立完成高質量數據供給;從治理角度看,數據壟斷與數據鴻溝問題日益突出,推動建立以公共價值為導向的開放機制成為現實選擇。由此,也不難發現開放數據集生態在當前的戰略價值。在國家層面,開放數據集生態是實現數據主權與技術自立的重要抓手;在產業層面,開放數據集生態連接算法能力與落地場景,是技術轉化為生產力的關鍵紐帶;在社會層面,開放數據集生態為提升治理效率和公共服務質量提供了底層支撐。從全球來看,開放數據集生態也正成為國際合作、文化交流和治理對話的重要基礎,體現出從資源共享走向制度共建的深層邏輯。
二、開放數據集生態框架:關鍵角色與分工定位
開放數據集生態的建設是一項系統性工程,需要多方參與、協同推進。在開放數據集生態中存在關鍵角色:
第一類是數據提供者,主要包括政府部門、科研院所、醫療機構、企業組織等,負責數據的產生、脫敏處理和基礎標準化,是開放數據集生態的源頭。
第二類是平臺運營方,如國家或地方的數據平臺、行業協會建設的數據湖、社區驅動的開源數據集項目,承擔數據的整合、發布、接口設計和質量控制,是連接供需的樞紐。
第三類是數據使用者,包括高校、科研團隊、AI企業等,他們通過使用數據推動技術研發與模型訓練,同時提出反饋與改進建議,促進數據集迭代。
第四類是制度建設與監管方,如立法機構、數據治理委員會、隱私保護組織,制定相關政策標準,確保數據開放合法合規,維護各方權益。
第五類是公眾與眾包參與者,包括數據標注人員、普通用戶、自愿上傳者等,他們通過參與標注、驗證和反饋等行為,激發數據生態的活力與持續性。
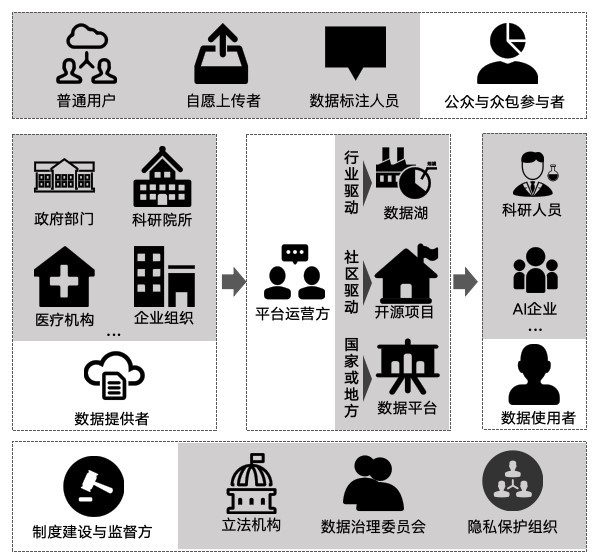
圖 1 開放數據集生態關鍵角色
以一個智能醫療影像診斷項目為例,當某地區突發罕見傳染病時,醫療機構與科研單位作為核心數據提供者,可以率先開放匿名化處理的CT影像數據,企業同步共享設備采集的歷史影像庫,經統一標準格式轉換后形成基礎數據集。
平臺運營方依托國家醫學數據中心打造專項平臺,通過分級訪問接口、沙箱環境與自動化質檢系統連接供需兩端。例如,平臺運營方可以設置差異化權限機制——普通研究者僅能訪問部分樣本,授權機構則可以獲得完整的數據支持。
數據使用者在實際應用中持續驅動生態優化。例如,醫療AI企業在模型訓練中發現兒童病例識別準確率不足60%,隨即提出分年齡段數據增強訴求,促使平臺開辟兒童病例專用通道;高校團隊研發的新型標注工具提升肺泡病變標注效率,并反向注入數據,這可以進一步強化數據集的價值密度。
監管方通過動態規則守護系統安全邊界。隱私保護組織開發的加密模塊確保數據查詢的最小單元量,避免個人身份泄露風險。醫療倫理委員會設置的智能熔斷機制,則能對異常數據訪問行為實施必要的實時干預。
公眾參與同樣賦予生態獨特活力。醫學院學生通過模擬診斷實踐課程貢獻標注軌跡,康復患者自愿上傳隨訪影像完善療效評估體系,形成公眾智慧與專業知識的共振。尤為關鍵的是,當放射科專家同時以數據使用者與提供者身份推動“臨床反饋-模型迭代”的雙周循環機制時,監管方同步出臺《動態更新規范》,在保障系統持續進化的同時防控未知風險。這種多角色身份轉換與協同演化,最終催生出融合原始數據與群體智能的加密知識圖譜,既服務于診斷模型升級,又反哺新一代醫療設備研發。
在開放數據集生態中,這些參與方的角色并非一成不變,而是多元身份并存、協同演化。例如,科研人員既可能作為數據使用者,也可能通過課題研究反哺高質量數據集開發;政府既是平臺建設者,也是規則制定者。當前,開放數據集的生態架構也正從“數據收集—平臺聚合—模型訓練”線性路徑,轉向“數據共建—知識共創—智能共融”的網絡結構,形成數據流、知識流與價值流交織的閉環體系。
三、開放數據集生態演化:潛在挑戰與未來展望
盡管開放數據集生態前景廣闊,但其發展仍面臨諸多挑戰。我國南方某經濟大省作為數據開放的先行省份,在開放數據集生態建設方面積累了寶貴的試點經驗,同時也經歷了諸多不易:
一是數據可得性與結構性失衡。高價值數據大多集中在政府與大型企業,受限于隱私、法律或利益因素難以廣泛開放;而對數據需求強烈的中小機構與科研團隊,則難以獲取足量、結構化、可用性高的數據資源,造成供需錯位。很多省市大量存在數據集零下載問題,部分地方的零下載率超過50%。一些地方政府發布的“機構權責清單信息”等數據集因缺乏實用價值而被長期閑置,企業業務創新急需的交通、醫療等動態數據卻未充分開放。
二是標準缺失與技術協同不足。當前,不同平臺之間依然缺少統一的數據格式與接口標準,不同數據集之間難以互通共享。數據脫敏不徹底、元數據缺失、版本追溯困難、質量評估體系薄弱等問題制約了數據集的可信度與可用性。數據質量參差不齊,缺乏完善的評估體系和追溯機制;平臺間互操作性差,制約了數據集的整合利用。此外,制度滯后也加劇了開發者的不確定性,限制了數據集的廣泛使用。在一些地方政府的數據開放平臺中,往往只有三、四成數據集采用可機讀的CSV格式,遠低于國家要求的90%,大量XLS/XLSX文件需人工解析,增加了數據集利用的技術門檻。MIT研究顯示,全球主流AI訓練數據集(如C4、Dolma)中,25%的網頁因robots.txt限制或服務條款矛盾,導致數據抓取合法性存疑,加劇了數據碎片化。
三是生態激勵與可持續性不足。在現有的框架下,缺乏對數據貢獻方的明確的激勵機制,也沒有形成“數據即資產”的價值認知體系。與此同時,平臺維護成本高、用戶活躍度不足等問題,可能導致生態“建而不用”“用而不養”,對平臺維護方缺乏可持續商業模式,易陷入“流量低迷—維護乏力—服務降級”的惡性循環,影響生態粘性與整體質量。在一些地方政府數據開放平臺中,有超過6成以上的數據集未被及時更新,部分地方因所發布的開放數據集維護成本高、維護不及時而導致數據時效性下降。國內大多數的數據交易平臺中,往往是僅有小部分企業持續貢獻數據更新。
為此,未來開放數據集生態應朝著更加智能化、制度化與普惠化的方向演進。
首先,未來開放數據生態的智能化協同機制將構筑數據要素流通的革新范式。依托聯邦學習架構、多方安全計算協議與智能合約機制的復合技術矩陣,未來開放屬于生態將構建起數權明晰且價值貫通的智慧協作網絡,探索數據可用不可見的新型實踐路徑。這種技術融合不僅破解了傳統數據共享中隱私保護與價值釋放的二元對立,更通過分布式智能節點的有機協同,形成覆蓋數據萃取、知識沉淀與價值聚合的全鏈路增值體系。
其次,未來開放數據集生態的制度化運作體系將鑄就生態治理的堅實基座。為此,需要構建起包含數據主權分級框架、質量認證體系、算法治理規范、倫理審查機制的四維制度架構,形成剛柔并濟的治理范式。其中既涵蓋數據要素三權分置等產權制度改革,也包含動態演進的監管沙盒機制。通過規范性與靈活性并重的制度設計,在公共利益與私人權益之間探尋動態平衡點,使治理體系兼具制度剛性與實踐彈性。
最后,未來開放數據集生態的普惠化進程將重構數字社會的參與范式。借助分布式眾包平臺與社區共創機制,推動公眾完成從“數據集消費者”向“數據集共建者”的角色躍遷。這種轉變既體現在公眾通過可視化工具參與城市治理的數字民主實踐,也反映在區塊鏈賦能的貢獻確權體系之中。當每位參與者的數據行為都能映射為可量化的價值坐標,當專業知識與群體智慧在交互中持續反哺,最終將孵化出人機共生、多元共治的數據集生態共同體。

總結而言,開放數據集生態是未來人工智能技術演進與治理創新的重要平臺。它不僅為模型訓練提供高質量數據資源,更通過協同機制連接起政府、產業、科研與社會的多方力量,構建出一個有機生長的智能共同體。誰能率先建成高質量、制度化、可持續的開放數據體系,誰就將在智能時代搶占創新高地與治理主動權。
基金項目:國家社會科學基金重點項目“基于數智融合的信息分析方法創新與應用”;國家檔案局科技項目“基于生成式人工智能的檔案數據化關鍵方法及其應用研究”。
致謝:感謝中國人民大學信息資源管理學院博士研究生郭姝麟在本文完成過程中所提供的資料收集與整理支持。
